【设计模式之美】(四)规范与重构
规范与重构
为什么要重构
⾸先,重构是时刻保证代码质量的⼀个极其有效的⼿段,不⾄于让代码腐化到⽆可救药的地步。项⽬在演进,代码不停地在堆砌。如果没有⼈为代码的质量负责任,代码总是会往越来越混乱的⽅向演进。当混乱到⼀定程度之后,量变引起质变,项⽬的维护成本已经⾼过重新开发⼀套新代码的成本,想要再去重构,已经没有⼈能做到了。
其次,优秀的代码或架构不是⼀开始就能完全设计好的,就像优秀的公司和产品也都是迭代出来的。我们⽆法100% 遇⻅未来的需求,也没有⾜够的精⼒、时间、资源为遥远的未来买单,所以,随着系统的演进,重构代码也是不可避免的。
重构是避免过度设计的有效⼿段。在我们维护代码的过程中,真正遇到问题的时候,再对代码进⾏重构,能有效避免前期投⼊太多时间做过度的设计,做到有的放⽮。
除此之外,重构对⼀个⼯程师本身技术的成⻓也有重要的意义。
从前⾯我给出的重构的定义来看,重构实际上是对我们学习的经典设计思想、设计原则、设计模式、编程规范的⼀种应⽤。重构实际上就是将这些理论知识,应⽤到实践的⼀个很好的场景,能够锻炼我们熟练使⽤这些理论知识的能⼒。除此之外,平时堆砌业务逻辑,你可能总觉得没啥成⻓,⽽将⼀个⽐较烂的代码重构成⼀个⽐较好的代码,会让你很有成就感。
重构的对象
根据重构的规模,我们可以笼统地分为⼤规模⾼层次重构(以下简称为“⼤型重构”)和⼩规模低层次的重构(以下简称为“⼩型重构”)。
⼤型重构指的是对顶层代码设计的重构,包括:系统、模块、代码结构、类与类之间的关系等的重构,重构的⼿段有:分层、模块化、解耦、抽象可复⽤组件等等。这类重构的⼯具就是我们学习过的那些设计思想、原则和模式。这类重构涉及的代码改动会⽐较多,影响⾯会⽐较⼤,所以难度也较⼤,耗时会⽐较⻓,引⼊ bug 的⻛险也会相对⽐较⼤。
⼩型重构指的是对代码细节的重构,主要是针对类、函数、变量等代码级别的重构,⽐如规范命名、规范注释、消除超⼤类或函数、提取重复代码等等。⼩型重构更多的是利⽤我们能后⾯要讲到的编码规范。这类重构要修改的地⽅⽐较集中,⽐较简单,可操作性较强,耗时会⽐较短,引⼊ bug 的⻛险相对来说也会⽐较⼩。你只需要熟练掌握各种编码规范,就可以做到得⼼应⼿。
什么时候重构
搞清楚了为什么重构,到底重构什么,我们再来看⼀下,什么时候重构?是代码烂到⼀定程度之后才去重构吗?当然不是。因为当代码真的烂到出现“开发效率低,招了很多⼈,天天加班,出活却不多,线上 bug 频发,领导发飙,中层束⼿⽆策,⼯程师抱怨不断,查找 bug 困难”的时候,基本上重构也⽆法解决问题了。
我个⼈⽐较反对,平时不注重代码质量,堆砌烂代码,实在维护不了了就⼤⼑阔斧地重构、甚⾄重写的⾏为。有时候项⽬代码太多了,重构很难做得彻底,最后⼜搞出来⼀个“四不像的怪物”,这就更麻烦了!所以,寄希望于在代码烂到⼀定程度之后,集中重构解决所有问题是不现实的,我们必须探索⼀条可持续、可演进的⽅式。
所以,我特别提倡的重构策略是持续重构。这也是我在⼯作中特别喜欢⼲的事情。平时没有事情的时候,你可以看看项⽬中有哪些写得不够好的、可以优化的代码,主动去重构⼀下。或者,在修改、添加某个功能代码的时候,你也可以顺⼿把不符合编码规范、不好的设计重构⼀下。总之,就像把单元测试、Code Review 作为开发的⼀部分,我们如果能把持续重构也作为开发的⼀部分,成为⼀种开发习惯,对项⽬、对⾃⼰都会很有好处。
尽管我们说重构能⼒很重要,但持续重构意识更重要。我们要正确地看待代码质量和重构这件事情。技术在更新、需求在变化、⼈员在流动,代码质量总会在下降,代码总会存在不完美,重构就会持续在进⾏。时刻具有持续重构意识,才能避免开发初期就过度设计,避免代码维护的过程中质量的下降。⽽那些看到别⼈代码有点瑕疵就⼀顿乱骂,或者花尽⼼思去构思⼀个完美设计的⼈,往往都是因为没有树⽴正确的代码质量观,没有持续重构意识。
如何重构
前⾯我们讲到,按照重构的规模,重构可以笼统地分为⼤型重构和⼩型重构。对于这两种不同规模的重构,我们要区别对待。
对于⼤型重构来说,因为涉及的模块、代码会⽐较多,如果项⽬代码质量⼜⽐较差,耦合⽐较严重,往往会牵⼀发⽽动全身,本来觉得⼀天就能完成的重构,你会发现越改越多、越改越乱,没⼀两个礼拜都搞不定。⽽新的业务开发⼜与重构相冲突,最后只能半途⽽废,revert 掉所有的改动,很失落地⼜去堆砌烂代码了。
在进⾏⼤型重构的时候,我们要提前做好完善的重构计划,有条不紊地分阶段来进⾏。每个阶段完成⼀⼩部分代码的重构,然后提交、测试、运⾏,发现没有问题之后,再继续进⾏下⼀阶段的重构,保证代码仓库中的代码⼀直处于可运⾏、逻辑正确的状态。每个阶段,我们都要控制好重构影响到的代码范围,考虑好如何兼容⽼的代码逻辑,必要的时候还需要写⼀些兼容过渡代码。只有这样,我们才能让每⼀阶段的重构都不⾄于耗时太⻓(最好⼀天就能完成),不⾄于与新的功能开发相冲突。
⼤规模⾼层次的重构⼀定是有组织、有计划,并且⾮常谨慎的,需要有经验、熟悉业务的资深同事来主导。⽽⼩规模低层次的重构,因为影响范围⼩,改动耗时短,所以,只要你愿意并且有时间,随时都可以去做。实际上,除了⼈⼯去发现低层次的质量问题,我们还可以借助很多成熟的静态代码分析⼯具(⽐如 CheckStyle、FindBugs、PMD),来⾃动发现代码中的问题,然后针对性地进⾏重构优化。
对于重构这件事情,资深的⼯程师、项⽬ leader 要负起责任来,没事就重构⼀下代码,时刻保证代码质量处在⼀个良好的状态。否则,⼀旦出现“破窗效应”,⼀个⼈往⾥堆了⼀些烂代码,之后就会有更多的⼈往⾥堆更烂的代码。毕竟往项⽬⾥堆砌烂代码的成本太低了。不过,保持代码质量最好的⽅法还是打造⼀种好的技术氛围,以此来驱动⼤家主动去关注代码质量,持续重构代码。
解耦为什么重要
软件设计与开发最重要的⼯作之⼀就是应对复杂性。⼈处理复杂性的能⼒是有限的。过于复杂的代码往往在可读性、可维护性上都不友好。那如何来控制代码的复杂性呢?⼿段有很多,我个⼈认为,最关键的就是解耦,保证代码松耦合、⾼内聚。如果说重构是保证代码质量不⾄于腐化到⽆可救药地步的有效⼿段,那么利⽤解耦的⽅法对代码重构,就是保证代码不⾄于复杂到⽆法控制的有效⼿段。
代码是否需要“解耦”?
间接的衡量标准有很多,前⾯我们讲到了⼀些,⽐如,看修改代码会不会牵⼀发⽽动全身。除此之外,还有⼀个直接的衡量标准,也是我在阅读源码的时候经常会⽤到的,那就是把模块与模块之间、类与类之间的依赖关系画出来,根据依赖关系图的复杂性来判断是否需要解耦重构。
如果依赖关系复杂、混乱,那从代码结构上来讲,可读性和可维护性肯定不是太好,那我们就需要考虑是否可以通过解耦的⽅法,让依赖关系变得清晰、简单。当然,这种判断还是有⽐较强的主观⾊彩,但是可以作为⼀种参考和梳理依赖的⼿段,配合间接的衡量标准⼀块来使⽤。
如何给代码解耦
封装与抽象
封装和抽象作为两个⾮常通⽤的设计思想,可以应⽤在很多设计场景中,⽐如系统、模块、lib、组件、接⼝、类等等的设计。封装和抽象可以有效地隐藏实现的复杂性,隔离实现的易变性,给依赖的模块提供稳定且易⽤的抽象接⼝。
⽐如,Unix 系统提供的 open() ⽂件操作函数,我们⽤起来⾮常简单,但是底层实现却⾮常复杂,涉及权限控制、并发控制、物理存储等等。我们通过将其封装成⼀个抽象的 open() 函数,能够有效控制代码复杂性的蔓延,将复杂性封装在局部代码中。除此之外,因为 open() 函数基于抽象⽽⾮具体的实现来定义,所以我们在改动 open() 函数的底层实现的时候,并不需要改动依赖它的上层代码,也符合我们前⾯提到的“⾼内聚、松耦合”代码的评判标准。
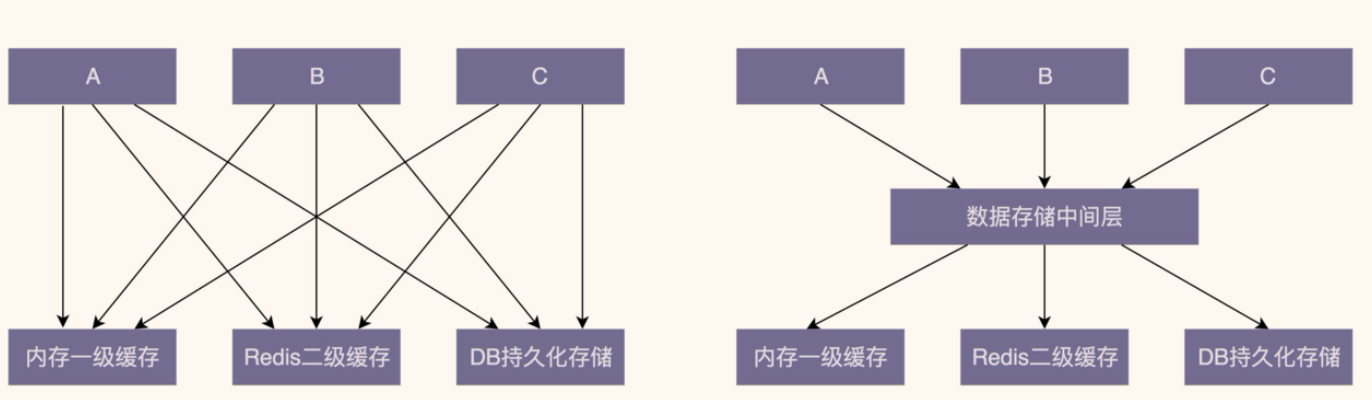
中间层
引⼊中间层能简化模块或类之间的依赖关系。下⾯这张图是引⼊中间层前后的依赖关系对⽐图。在引⼊数据存储中间层之前,A、B、C 三个模块都要依赖内存⼀级缓存、Redis ⼆级缓存、DB 持久化存储三个模块。在引⼊中间层之后,三个模块只需要依赖数据存储⼀个模块即可。从图上可以看出,中间层的引⼊明显地简化了依赖关系,让代码结构更加清晰。
除此之外,我们在进⾏重构的时候,引⼊中间层可以起到过渡的作⽤,能够让开发和重构同步进⾏,不互相⼲扰。⽐如,某个接⼝设计得有问题,我们需要修改它的定义,同时,所有调⽤这个接⼝的代码都要做相应的改动。如果新开发的代码也⽤到这个接⼝,那开发就跟重构冲突了。为了让重构能⼩步快跑,我们可以分下⾯四个阶段来完成接⼝的修改。
1 | 第⼀阶段:引⼊⼀个中间层,包裹⽼的接⼝,提供新的接⼝定义。 |
模块化
模块化是构建复杂系统常⽤的⼿段。不仅在软件⾏业,在建筑、机械制造等⾏业,这个⼿段也⾮常有⽤。对于⼀个⼤型复杂系统来说,没有⼈能掌控所有的细节。之所以我们能搭建出如此复杂的系统,并且能维护得了,最主要的原因就是将系统划分成各个独⽴的模块,让不同的⼈负责不同的模块,这样即便在不了解全部细节的情况下,管理者也能协调各个模块,让整个系统有效运转。
聚焦到软件开发上⾯,很多⼤型软件(⽐如 Windows)之所以能做到⼏百、上千⼈有条不紊地协作开发,也归功于模块化做得好。不同的模块之间通过 API 来进⾏通信,每个模块之间耦合很⼩,每个⼩的团队聚焦于⼀个独⽴的⾼内聚模块来开发,最终像搭积⽊⼀样将各个模块组装起来,构建成⼀个超级复杂的系统。
我们再聚焦到代码层⾯。合理地划分模块能有效地解耦代码,提⾼代码的可读性和可维护性。所以,我们在开发代码的时候,⼀定要有模块化意识,将每个模块都当作⼀个独⽴的 lib ⼀样来开发,只提供封装了内部实现细节的接⼝给其他模块使⽤,这样可以减少不同模块之间的耦合度。
实际上,从刚刚的讲解中我们也可以发现,模块化的思想⽆处不在,像 SOA、微服务、lib 库、系统内模块划分,甚⾄是类、函数的设计,都体现了模块化思想。如果追本溯源,模块化思想更加本质的东⻄就是分⽽治之。
其他设计思想和原则
“⾼内聚、松耦合”是⼀个⾮常重要的设计思想,能够有效提⾼代码的可读性和可维护性,缩⼩功能改动导致的代码改动范围。实际上,在前⾯的章节中,我们已经多次提到过这个设计思想。很多设计原则都以实现代码的“⾼内聚、松耦合”为⽬的。我们来⼀块总结回顾⼀下都有哪些原则。
- 单⼀职责原则
我们前⾯提到,内聚性和耦合性并⾮独⽴的。⾼内聚会让代码更加松耦合,⽽实现⾼内聚的重要指导原则就是单⼀职责原则。模块或者类的职责设计得单⼀,⽽不是⼤⽽全,那依赖它的类和它依赖的类就会⽐较少,代码耦合也就相应的降低了。 - 基于接⼝⽽⾮实现编程
基于接⼝⽽⾮实现编程能通过接⼝这样⼀个中间层,隔离变化和具体的实现。这样做的好处是,在有依赖关系的两个模块或类之间,⼀个模块或者类的改动,不会影响到另⼀个模块或类。实际上,这就相当于将⼀种强依赖关系(强耦合)解耦为了弱依赖关系(弱耦合)。 - 依赖注⼊
跟基于接⼝⽽⾮实现编程思想类似,依赖注⼊也是将代码之间的强耦合变为弱耦合。尽管依赖注⼊⽆法将本应该有依赖关系的两个类,解耦为没有依赖关系,但可以让耦合关系没那么紧密,容易做到插拔替换。 - 多⽤组合少⽤继承
我们知道,继承是⼀种强依赖关系,⽗类与⼦类⾼度耦合,且这种耦合关系⾮常脆弱,牵⼀发⽽动全身,⽗类的每⼀次改动都会影响所有的⼦类。相反,组合关系是⼀种弱依赖关系,这种关系更加灵活,所以,对于继承结构⽐较复杂的代码,利⽤组合来替换继承,也是⼀种解耦的有效⼿段。 - 迪⽶特法则
迪⽶特法则讲的是,不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接⼝。从定义上,我们明显可以看出,这条原则的⽬的就是为了实现代码的松耦合。
除了上⾯讲到的这些设计思想和原则之外,还有⼀些设计模式也是为了解耦依赖,⽐如观察者模式,有关这⼀部分的内容,我们留在设计模式模块中慢慢讲解。
快速改善代码质量的20条编程规范
关于命名
- 命名的关键是能准确达意。对于不同作⽤域的命名,我们可以适当地选择不同的⻓度。
- 我们可以借助类的信息来简化属性、函数的命名,利⽤函数的信息来简化函数参数的命名。
- 命名要可读、可搜索。不要使⽤⽣僻的、不好读的英⽂单词来命名。命名要符合项⽬的统⼀规范,也不要⽤些反直觉的命名。
- 接⼝有两种命名⽅式:⼀种是在接⼝中带前缀“I”;另⼀种是在接⼝的实现类中带后缀“Impl”。对于抽象类的命名,也有两种⽅式,⼀种是带上前缀“Abstract”,⼀种是不带前缀。这两种命名⽅式都可以,关键是要在项⽬中统⼀。
关于注释
- 注释的内容主要包含这样三个⽅⾯:做什么、为什么、怎么做。对于⼀些复杂的类和接⼝,我们可能还需要写明“如何⽤”。
- 类和函数⼀定要写注释,⽽且要写得尽可能全⾯详细。函数内部的注释要相对少⼀些,⼀般都是靠好的命名、提炼函数、解释性变量、总结性注释来提⾼代码可读性。
- 关于代码⻛格
- 函数、类多⼤才合适?函数的代码⾏数不要超过⼀屏幕的⼤⼩,⽐如 50 ⾏。类的⼤⼩限制⽐较难确定。
- ⼀⾏代码多⻓最合适?最好不要超过 IDE 的显示宽度。当然,也不能太⼩,否则会导致很多稍微⻓点的语句被折成两⾏,也会影响到代码的整洁,不利于阅读。
- 善⽤空⾏分割单元块。对于⽐较⻓的函数,为了让逻辑更加清晰,可以使⽤空⾏来分割各个代码块。
- 四格缩进还是两格缩进?我个⼈⽐较推荐使⽤两格缩进,这样可以节省空间,尤其是在代码嵌套层次⽐较深的情况下。不管是⽤两格缩进还是四格缩进,⼀定不要⽤ tab 键缩进。
- ⼤括号是否要另起⼀⾏?将⼤括号放到跟上⼀条语句同⼀⾏,可以节省代码⾏数。但是将⼤括号另起新的⼀⾏的⽅式,左右括号可以垂直对⻬,哪些代码属于哪⼀个代码块,更加⼀⽬了然。
- 类中成员怎么排列?在 Google Java 编程规范中,依赖类按照字⺟序从⼩到⼤排列。类中先写成员变量后写函数。成员变量之间或函数之间,先写静态成员变量或函数,后写普通变量或函数,并且按照作⽤域⼤⼩依次排列。
关于编码技巧
- 将复杂的逻辑提炼拆分成函数和类。
- 通过拆分成多个函数或将参数封装为对象的⽅式,来处理参数过多的情况。
- 函数中不要使⽤参数来做代码执⾏逻辑的控制。
- 函数设计要职责单⼀。
- 移除过深的嵌套层次,⽅法包括:去掉多余的 if 或 else 语句,使⽤ continue、break、return 关键字提前退出嵌套,调整执⾏顺序来减少嵌套,将部分嵌套逻辑抽象成函数。
- ⽤字⾯常量取代魔法数。
- ⽤解释性变量来解释复杂表达式,以此提⾼代码可读性。
统⼀编码规范
- 除了这三节讲到的⽐较细节的知识点之外,最后,还有⼀条⾮常重要的,那就是,项⽬、团队,甚⾄公司,⼀定要制定统⼀的编码规范,并且通过 Code Review 督促执⾏,这对提⾼代码质量有⽴竿⻅影的效果。
如何发现代码质量问题
如何发现代码质量问题 · 常规checklist
- 目录设置是否合理、模块划分是否清晰、代码结构是否满足“高内聚、松耦合”?
- 是否遵循经典的设计原则喝设计思想(SOLID, DRY, KISS, YAGNI, LOD等)?
- 设计模式是否应用得当?是否有过度设计?
- 代码是否容易扩展?如果要添加新功能,是否容易实现?
- 代码是否可以复用?是否可以复用已有的项目代码或类库?是否有重复造轮子?
- 代码是否容易测试?单元测试是否全面覆盖各种正常和异常的情况?
- 代码是否易读?是否符合编码规范(比如命名和注释是否恰当、代码风格是否一致等)?
如何发现代码质量问题 · 业务需求checklist
- 代码是否实现了预期的业务需求?
- 逻辑是否正确?是否处理了各种异常情况?
- 日志打印是否得当?是否方便debug排查问题?
- 接口是否易用?是否支持幂等、事务等
- 代码是否存在并发问题?是否线程安全?
- 性能是否有优化空间,比如,SQL、算法是否可以优化
- 是否有安全漏洞?比如,输入输出校验是否全面
关于重构思考
- 即便是⾮常简单的需求,不同⽔平的⼈写出来的代码,差别可能会很⼤。我们要对代码质量有所追求,不能只是凑活能⽤就好。花点⼼思写⼀段⾼质量的代码,⽐写 100 段凑活能⽤的代码,对你的代码能⼒提⾼更有帮助。
- 知其然知其所以然,了解优秀代码设计的演变过程,⽐学习优秀设计本身更有价值。知道为什么这么做,⽐单纯地知道怎么做更重要,这样可以避免你过度使⽤设计模式、思想和原则。
- 设计思想、原则、模式本身并没有太多“⾼⼤上”的东⻄,都是⼀些简单的道理,⽽且知识点也并不多,关键还是锻炼具体代码具体分析的能⼒,把知识点恰当地⽤在项⽬中。
- 我经常讲,⾼⼿之间的竞争都是在细节。⼤的架构设计、分层、分模块思路实际上都差不多。没有项⽬是靠⼀些不为⼈知的设计来取胜的,即便有,很快也能被学习过去。所以,关键还是看代码细节处理得够不够好。这些细节的差别累积起来,会让代码质量有质的差别。所以,要想提⾼代码质量,还是要在细节处下功夫。
函数出错应该返回啥?
- 返回错误码:C语⾔没有异常这样的语法机制,返回错误码便是最常⽤的出错处理⽅式。⽽ Java、Python 等⽐较新的编程语⾔中,⼤部分情况下,我们都⽤异常来处理函数出错的情况,极少会⽤到错误码。
- 返回 NULL 值:在多数编程语⾔中,我们⽤ NULL 来表示“不存在”这种语义。对于查找函数来说,数据不存在并⾮⼀种异常情况,是⼀种正常⾏为,所以返回表示不存在语义的 NULL 值⽐返回异常更加合理。
- 返回空对象:返回 NULL 值有各种弊端,对此有⼀个⽐较经典的应对策略,那就是应⽤空对象设计模式。当函数返回的数据是字符串类型或者集合类型的时候,我们可以⽤空字符串或空集合替代 NULL 值,来表示不存在的情况。这样,我们在使⽤函数的时候,就可以不⽤做 NULL 值判断。
- 抛出异常对象:尽管前⾯讲了很多函数出错的返回数据类型,但是,最常⽤的函数出错处理⽅式是抛出异常。异常有两种类型:受检异常和⾮受检异常。
总之,是否往上继续抛出,要看上层代码是否关⼼这个异常。关⼼就将它抛出,否则就直接吞掉。是否需要包装成新的异常抛出,看上层代码是否能理解这个异常、是否业务相关。如果能理解、业务相关就可以直接抛出,否则就封装成新的异常抛出。



