@tvm.script.ir_module classMyModule: @T.prim_func defmm_relu(A: T.Buffer[(128, 128), "float32"], B: T.Buffer[(128, 128), "float32"], C: T.Buffer[(128, 128), "float32"]): T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True}) Y = T.alloc_buffer((128, 128), dtype="float32") for i, j, k in T.grid(128, 128, 128): with T.block("Y"): vi = T.axis.spatial(128, i) vj = T.axis.spatial(128, j) vk = T.axis.reduce(128, k) with T.init(): Y[vi, vj] = T.float32(0) Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj] for i, j in T.grid(128, 128): with T.block("C"): vi = T.axis.spatial(128, i) vj = T.axis.spatial(128, j) C[vi, vj] = T.max(Y[vi, vj], T.float32(0))
它实现的功能对应的numpy代码为:
1 2 3 4 5 6 7 8 9 10 11
deflnumpy_mm_relu(A: np.ndarray, B: np.ndarray, C: np.ndarray): Y = np.empty((128, 128), dtype="float32") for i inrange(128): for j inrange(128): for k inrange(128): if k == 0: Y[i, j] = 0 Y[i, j] = Y[i, j] + A[i, k] * B[k, j] for i inrange(128): for j inrange(128): C[i, j] = max(Y[i, j], 0)
/*! * \brief Primitive data types used in the low-level IR. * * PrimType represents POD-values and handles that are * not automatically managed by the runtime. * * \sa PrimType */ classPrimTypeNode : public TypeNode { public: /*! * \brief The corresponding dtype field. */ runtime::DataType dtype; ... };
/*! * \brief Function type. * * We support polymorphic function type. * This can be roughly viewed as template function in C++. * * \sa FuncType, TypeVar, TypeConstraint */ classFuncTypeNode : public TypeNode { public: /*! \brief typetype of arguments */ Array<Type> arg_types; /*! \brief The type of return value. */ Type ret_type; // The following fields are used in polymorphic(template) functions // For normal functions, the following two fields will be empty. /*! \brief The type parameters of the function */ Array<TypeVar> type_params; /*! * \brief potential constraint the type need to obey * \note this field is reserved for futher purposes. */ Array<TypeConstraint> type_constraints; ... };
/*! * \brief This is the most commonly used typein relay. * TensorType have a fixed dimension, data type. * * The elements of shape can be either IntImm(constant integer), * orany symbolic integer expression. * The symbolic integer allows generic shape inference in certain cases. * \sa TensorType */ classTensorTypeNode : public BaseTensorTypeNode { public: /*! * \brief The shape of the tensor, * represented by PrimExpr(tvm::Expr). */ Array<PrimExpr> shape; /*! \brief The content data type */ DataType dtype; ... }
classDynTensorTypeNode : public BaseTensorTypeNode { public: /*! * \brief The number of dimensions of the tensor, use -1 to denote tensor with unknwon number of * dimensions. */ int ndim; //现在直接定义ndim而不是shape /*! \brief The content data type, use void to denote the dtype is unknown. */ DataType dtype; ... };
/*! * \brief Base node of all primitive expressions. * * A primitive expression deals with low-level * POD data types and handles without * doing life-cycle management for objects. * * PrimExpr is used in the low-level code * optimizations and integer analysis. * * \sa PrimExpr */ classPrimExprNode : public BaseExprNode { public: // runtime::DataType(dtype) 在编译时和运行时提供粗粒度类型信息。 // 它动态地内置在 PrimExpr 表达式构造中,可用于快速类型检查。 // 当 PrimExpr 对应于 i32 等 POD 值类型时,dtype 足以决定 PrimExpr 的 Type。 // 当 dtype 为 DataType::Handle() 时,表达式可以对应更细粒度的 Type,我们可以通过lazy类型推断得到类型。 DataType dtype; }
// TODO(tvm-team): migrate low-level intrinsics to use Op /*! * \brief Primitive Op(builtin intrinsics) * * This data structure stores the meta-data * about primitive operators that can be invoked via Call. * * Low-level IR intrinsics(such as libc.expf) are also * implemented via Op. * * \sa Op */ classOpNode : public RelayExprNode { public: /*! \brief name of the operator */ String name; /*! \brief the type of the operator */ mutable FuncType op_type; /*! * \brief detailed description of the operator * This can be used to generate docstring automatically for the operator. */ String description; /* \brief Information of input arguments to the operator */ Array<AttrFieldInfo> arguments; /*! * \brief The type key of the attribute field * This can be empty, in which case it defaults to anything. */ String attrs_type_key; /*! * \brief attribute type index, * this field varies in each run andisnot exposed to frontend. */ uint32_t attrs_type_index{0}; /*! * \brief number of input arguments to the operator, * -1 means it is variable length */ int32_t num_inputs = -1; /*! * \brief support level of the operator, * The lower the more priority it contains. * This isin analogies to BLAS levels. */ int32_t support_level = 10; ... };
/*! * \brief IRModule that holds functions andtype definitions. * * IRModule is the basic unit forall IR transformations across the stack. * * Many operations require access to the global IRModule. * We pass the IRModule by value in a functional style as an explicit argument, * but we mutate the Module while optimizing programs. * \sa IRModule */ classIRModuleNode : public Object { public: /*! \brief A mapfrom ids to allglobal functions. */ Map<GlobalVar, BaseFunc> functions; /*! \brief A mapfromglobaltypevars to ADT type data. */ Map<GlobalTypeVar, TypeData> type_definitions; /*! \brief The source mapfor the module. */ parser::SourceMap source_map; /* \brief Additional attributes storing meta-data about the module. */ DictAttrs attrs; ... }
using Expr = tvm::RelayExpr; using ExprNode = tvm::RelayExprNode; using BaseFunc = tvm::BaseFunc; using BaseFuncNode = tvm::BaseFuncNode; using GlobalVar = tvm::GlobalVar; using GlobalVarNode = tvm::GlobalVarNode; using tvm::PrettyPrint;
/*! \brief Container for Var */ classVarNode : public ExprNode { public: /*! * \brief The unique identifier of the Var. * * vid will be preserved for the same Var during type inference * and other rewritings, while the VarNode might be recreated * to attach additional information. * This property can be used to keep track of parameter Var * information across passes. */ Id vid; /*! * \brief type annotaion of the variable. * This field records user provided type annotation of the Var. * This field is optional and can be None. */ Type type_annotation;
/*! \return The name hint of the variable */ const String& name_hint()const{ return vid->name_hint; } };
/*! * \brief Relay Function container * \sa Function */ classFunctionNode : public BaseFuncNode { public: /*! \brief Function parameters */ tvm::Array<Var> params; /*! * \brief * The expression which represents the computation of the function, * the expression may reference the parameters, and the type of it * or sub-expressions may reference the type variables. */ Expr body; /*! \brief User annotated return type of the function. */ Type ret_type; /*! * \brief Type parameters of the function. * Enables the function to vary its type based on these. * This corresponds to template paramaters in c++'s terminology. * * \note This can be usually empty for non-polymorphic functions. */ tvm::Array<TypeVar> type_params; }
/*! * \brief Add a 1D Tensor to an axis of a data. * * \note bias_add is a special add operator that is in nn * and enables automatic derivation of bias's shape. * You can directly use add for more generalized case. */ structBiasAddAttrs : public tvm::AttrsNode<BiasAddAttrs> { int axis;
TVM_DECLARE_ATTRS(BiasAddAttrs, "relay.attrs.BiasAddAttrs") { TVM_ATTR_FIELD(axis).describe("The axis to add the bias").set_default(1); } };
boolBiasAddRel(const Array<Type>& types, int num_inputs, const Attrs& attrs, const TypeReporter& reporter){ ICHECK_EQ(types.size(), 3); constauto* data = types[0].as<TensorTypeNode>(); if (data == nullptr) returnfalse;
const BiasAddAttrs* param = attrs.as<BiasAddAttrs>(); ICHECK(param != nullptr); int axis = param->axis; if (axis < 0) { axis = data->shape.size() + axis; } if (axis >= static_cast<int>(data->shape.size()) || axis < 0) { reporter->GetDiagCtx().EmitFatal(Diagnostic::Error(reporter->GetSpan()) << "The axis in bias_add must be in range for the shape; " << "attempted to access index " << param->axis << " of " << PrettyPrint(data->shape)); returnfalse; }
/*! * \brief Operator implementation that includes compute and schedule function. */ classOpImplementationNode : public Object { public: /*! \brief Compute function */ FTVMCompute fcompute; /*! \brief Schedule function */ FTVMSchedule fschedule; /*! \brief Name of the implementation */ String name; /*! \brief Priority level */ int plevel;
/*! * \brief Specialized implementations for operators under certain conditions. */ classOpSpecializationNode : public Object { public: /*! \brief List of implementations. */ Array<OpImplementation> implementations; /*! \brief Condition to enable the specialization. * Could be undefined to represent generic case. */ te::SpecializedCondition condition;
/*! * \brief Operator strategy class. */ classOpStrategy : public ObjectRef { public: /*! * \brief Add an implementation. * \param fcompute Compute function * \param fschedule Schedule function * \param name Name of the implementation * \param plevel Priority level of the implementation */ TVM_DLL voidAddImplementation(FTVMCompute fcompute, FTVMSchedule fschedule, String name, int plevel);
RELAY_REGISTER_OP("nn.conv1d") .describe(R"code(1D convolution layer (e.g. spatial convolution over sequences). This layer creates a convolution kernel that is convolved with the layer input to produce a tensor of outputs. - **data**: This depends on the `layout` parameter. Input is 3D array of shape (batch_size, in_channels, width) if `layout` is `NCW`. - **weight**: (channels, in_channels, kernel_size) - **out**: This depends on the `layout` parameter. Output is 3D array of shape (batch_size, channels, out_width) if `layout` is `NCW`. )code" TVM_ADD_FILELINE) .set_attrs_type<Conv1DAttrs>() .set_num_inputs(2) .add_argument("data", "Tensor", "The input tensor.") .add_argument("weight", "Tensor", "The weight tensor.") .set_support_level(2) .add_type_rel("Conv1D", Conv1DRel) .set_attr<FInferCorrectLayout>("FInferCorrectLayout", ConvInferCorrectLayout<Conv1DAttrs>) .set_attr<TOpPattern>("TOpPattern", kOutEWiseFusable);
import tvm.script from tvm.script import tir as T, relax as R
@tvm.script.ir_module classMyIRModule: @T.prim_func deftir_exp_func(x: T.handle, y: T.handle): ## <= D2 X = T.match_buffer(x, (n,), "float32") Y = T.match_buffer(y, (n,), "float32") with T.grid(n) as i: Y[i] = T.exp(X[i])
@R.function defrelax_func(x: R.Tensor[(n, k), "f32"], w: R.Tensor[_, "f32"]): # n, k above are implicitly defined by the signature # so we will be able to refer to n, k in the later part of the program with R.dataflow(): ### <= D0 lv0 = R.match_shape(w, (k, m)) ## <= D1 lv1: R.Tensor[(n, m), "f32"] = R.dot(x, lv0) lv2: R.Tensor[(n * m,), "f32"] = R.flatten(lv1) ## <= D1 lv3: R.Shape = (n * m,) ## <= D1 gv0: R.Tensor[lv2, "f32"] = R.call_tir(lv2, tir_exp_func, [lv3]) ## <= D2 R.outputs(gv0)
@R.function defshape_example(x: R.Tensor[_, "f32"], y: R.Tensor[_, "f32"]): with R.dataflow(): # the match shape defines n, m because it appears for the first time lv0: R.Tensor[(n, m)] = R.match_shape(x, (n, m)) # the second occurance of n, m will translate into an assertion # that y's shape equals (n, m) lv1: R.Tensor[(n, m)] = R.match_shape(y, (n, m)) # we can also call match_shape on shape expressions lv2: Shape = R.match_shape(R.shape_of(y), (n, m))
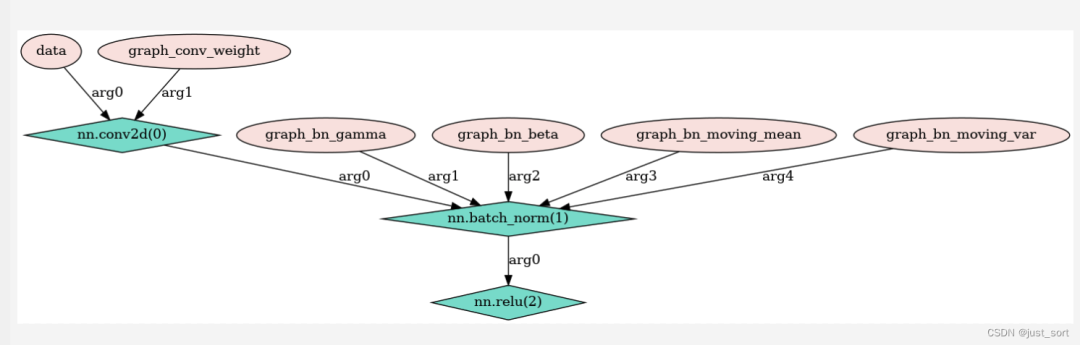
@tvm.script.ir_module classMyModule: @T.prim_func defmain(a: T.handle, b: T.handle): # We exchange data between function by handles, which are similar to pointer. T.func_attr({"global_symbol": "main", "tir.noalias": True}) # Create buffer from handles. A = T.match_buffer(a, (8,), dtype="float32") B = T.match_buffer(b, (8,), dtype="float32") for i inrange(8): # A block is an abstraction for computation. with T.block("B"): # Define a spatial block iterator and bind it to value i. vi = T.axis.spatial(8, i) B[vi] = A[vi] + 1.0
<class'tvm.ir.module.IRModule'> # from tvm.script import tir as T @tvm.script.ir_module classModule: @T.prim_func defmain(A: T.Buffer[8, "float32"], B: T.Buffer[8, "float32"]) -> None: # function attr dict T.func_attr({"global_symbol": "main", "tir.noalias": True}) # body # with T.block("root") for i in T.serial(8): with T.block("B"): vi = T.axis.spatial(8, i) T.reads(A[vi]) T.writes(B[vi]) B[vi] = A[vi] + T.float32(1)
# from tvm.script import tir as T @tvm.script.ir_module classModule: @T.prim_func defmain(A: T.Buffer[8, "float32"], B: T.Buffer[8, "float32"]) -> None: # function attr dict T.func_attr({"global_symbol": "main", "tir.noalias": True}) # body # with T.block("root") for i0 in T.serial(8): with T.block("B"): i0_1 = T.axis.spatial(8, i0) T.reads(A[i0_1]) T.writes(B[i0_1]) B[i0_1] = A[i0_1] + T.float32(1)
defcompute(shape, fcompute, name="compute", tag="", attrs=None, varargs_names=None): """Construct a new tensor by computing over the shape domain. The compute rule is result[axis] = fcompute(axis) Parameters ---------- shape: Tuple of Expr The shape of the tensor fcompute: lambda function of indices-> value Specifies the input source expression name: str, optional The name hint of the tensor tag: str, optional Additional tag information about the compute. attrs: dict, optional The additional auxiliary attributes about the compute. varargs_names: list, optional The names to use for each of the varargs. If not supplied, the varargs will be called i1, i2, ... Returns ------- tensor: Tensor The created tensor """ if _tag.TagScope.get_current() isnotNone: if tag != "": raise ValueError("nested tag is not allowed for now") tag = _tag.TagScope.get_current().tag shape = (shape,) ifisinstance(shape, tvm.tir.PrimExpr) else shape # for python3 shape = tuple([int(s) ifisinstance(s, float) else s for s in shape]) out_ndim = len(shape) # 获取输入给lambda表达式的参数列表 argspec = inspect.getfullargspec(fcompute) iflen(argspec.args) == 0and argspec.varargs isNone: arg_names = ["i%d" % i for i inrange(out_ndim)] elif argspec.varargs isnotNone: # if there is a varargs, it takes the remaining dimensions of out_ndim num_remaining_args = out_ndim - len(argspec.args) if varargs_names isnotNone: iflen(varargs_names) != num_remaining_args: raise RuntimeError( f"Number of varargs ({num_remaining_args}) does not match number" f"of varargs_names ({len(varargs_names)})" ) arg_names = argspec.args + varargs_names else: arg_names = argspec.args + [f"i{i}"for i inrange(out_ndim - len(argspec.args))] else: arg_names = argspec.args # if there are fewer args than out dimensions, the remaining dimensions # are implicitly broadcast out_ndim = len(arg_names) assert argspec.varkw isNone, "Variable keyword arguments not supported in fcompute" assert argspec.defaults isNone, "Default arguments not supported in fcompute" assertlen(argspec.kwonlyargs) == 0, "Keyword arguments are not supported in fcompute"
if out_ndim != len(arg_names): raise ValueError( "Number of args to fcompute does not match dimension, " "args=%d, dimension=%d" % (len(arg_names), out_ndim) ) dim_var = [tvm.tir.IterVar((0, s), x, 0) for x, s inzip(arg_names, shape[:out_ndim])] # 基于lambda表达式创建List[PrimExpr] body = fcompute(*[v.var for v in dim_var]) # 将List[PrimExpr]传给TensorComputeOp进行计算并返回一个tvm.te.Tensor ifisinstance(body, _tensor.TensorIntrinCall): for i, s inenumerate(shape[out_ndim:]): var_name = "ax" + str(i) dim_var.append(tvm.tir.IterVar((0, s), var_name, 4)) op_node = _ffi_api.TensorComputeOp( name, tag, dim_var, body.reduce_axis, out_ndim, body.intrin, body.tensors, body.regions, body.scalar_inputs, ) else: ifnotisinstance(body, (list, tuple)): body = [body] body = convert(body) op_node = _ffi_api.ComputeOp(name, tag, attrs, dim_var, body)
num = op_node.num_outputs outputs = tuple(op_node.output(i) for i inrange(num)) return outputs[0] if num == 1else outputs
/*! * \brief PassNode is the base type of differnt types of optimization passes. * It is designed as a pure class and implemented by different pass subclasses * at different granularity of Relay nodes. */ classPassNode : public Object { public: virtual ~PassNode() {} /*! * \brief Get the pass information/meta data. */ virtual PassInfo Info()const= 0;
/*! * \brief Transform mod using the default PassContext in the current scope. * * \param mod The module that an optimization pass runs on. * * \return The transformed module. */ IRModule operator()(IRModule mod)const{ returnthis->operator()(std::move(mod), PassContext::Current()); } ... };
/*! * \brief Used to visit the types inside of expressions. * * Can be overloaded to transform the types in arbitrary * ways, one way would be to define a sub-class of type * visitor for types which transform them appropriately. */ virtual Type VisitType(const Type& t); virtual Clause VisitClause(const Clause& c); virtual Pattern VisitPattern(const Pattern& c);
protected: /*! \brief Internal map used for memoization. */ std::unordered_map<Expr, Expr, ObjectPtrHash, ObjectPtrEqual> memo_; };
classIf : public Expr { public: /*! * \brief The constructor * \param cond The condition of a if node. * \param true_branch The fall through branch * \param false_branch The branch for execution when condition is false. * \param span The source span of the expression. */ TVM_DLL If(Expr cond, Expr true_branch, Expr false_branch, Span span = Span());
/*! * \brief Module container of TVM. */ classModule : public ObjectRef { public: Module() {} // constructor from container. explicitModule(ObjectPtr<Object> n) : ObjectRef(n) {} /*! * \brief Get packed function from current module by name. * * \param name The name of the function. * \param query_imports Whether also query dependency modules. * \return The result function. * This function will return PackedFunc(nullptr) if function do not exist. * \note Implemented in packed_func.cc */ inline PackedFunc GetFunction(const std::string& name, bool query_imports = false); // The following functions requires link with runtime. /*! * \brief Import another module into this module. * \param other The module to be imported. * * \note Cyclic dependency is not allowed among modules, * An error will be thrown when cyclic dependency is detected. */ inlinevoidImport(Module other); ... };
// Module to support thread-safe multi-GPU execution. // cuModule is a per-GPU module // The runtime will contain a per-device module table // The modules will be lazily loaded // CUDAModuleNode对应到CUDA中的CUmodule classCUDAModuleNode : public runtime::ModuleNode { public: ... // 调用cuModuleGetFunction从CUmodule中获取kernel function handle PackedFunc GetFunction(const std::string& name, const ObjectPtr<Object>& sptr_to_self)final;
// 调用cuModuleGetGlobal从CUmodule中获取全局变量指针 CUdeviceptr GetGlobal(int device_id, const std::string& global_name, size_t expect_nbytes){ std::lock_guard<std::mutex> lock(mutex_); // must recheck under the lock scope if (module_[device_id] == nullptr) { CUDA_DRIVER_CALL(cuModuleLoadData(&(module_[device_id]), data_.c_str())); } CUdeviceptr global; size_t nbytes;
// invoke the function with void arguments voidoperator()(TVMArgs args, TVMRetValue* rv, void** void_args)const{ int device_id; CUDA_CALL(cudaGetDevice(&device_id)); ThreadWorkLoad wl = launch_param_config_.Extract(args);
if (fcache_[device_id] == nullptr) { fcache_[device_id] = m_->GetFunc(device_id, func_name_); if (wl.dyn_shmem_size >= (48 << 10)) { // Assumption: dyn_shmem_size doesn't change across different invocations of // fcache_[device_id] CUresult result = cuFuncSetAttribute( fcache_[device_id], CU_FUNC_ATTRIBUTE_MAX_DYNAMIC_SHARED_SIZE_BYTES, wl.dyn_shmem_size); if (result != CUDA_SUCCESS) { LOG(FATAL) << "Failed to set the allowed dynamic shared memory size to " << wl.dyn_shmem_size; } } } CUstream strm = static_cast<CUstream>(CUDAThreadEntry::ThreadLocal()->stream); CUresult result = cuLaunchKernel(fcache_[device_id], wl.grid_dim(0), wl.grid_dim(1), wl.grid_dim(2), wl.block_dim(0), wl.block_dim(1), wl.block_dim(2), wl.dyn_shmem_size, strm, void_args, nullptr); if (result != CUDA_SUCCESS && result != CUDA_ERROR_DEINITIALIZED) { constchar* msg; cuGetErrorName(result, &msg); std::ostringstream os; os << "CUDALaunch Error: " << msg << "\n" << " grid=(" << wl.grid_dim(0) << "," << wl.grid_dim(1) << "," << wl.grid_dim(2) << "), " << " block=(" << wl.block_dim(0) << "," << wl.block_dim(1) << "," << wl.block_dim(2) << ")\n"; std::string cuda = m_->GetSource(""); if (cuda.length() != 0) { os << "// func_name=" << func_name_ << "\n" << "// CUDA Source\n" << "// -----------\n" << cuda; } LOG(FATAL) << os.str(); } }
std::vector<std::pair<tvm::GlobalVar, tvm::BaseFunc>> funcs; for (auto kv : mod->functions) { // Make sure that the executor function is the last one to be code generated so that all the // symbols are available to __tvm_main__ auto fun_name = std::string(kv.first->name_hint); bool is_aot_executor_fn = kv.second->GetAttr<Bool>("runner_function", Bool(false)).value();
if (is_aot_executor_fn) { aot_executor_fn = Downcast<PrimFunc>(kv.second); continue; } funcs.push_back(kv); }
// Add all functions except __tvm_main__ // 把IRModule里所有的tir::PrimFunc都放到编译列表里面 for (auto& kv : funcs) { ICHECK(kv.second->IsInstance<PrimFuncNode>()) << "CodegenCHost: Can only take PrimFunc"; auto f = Downcast<PrimFunc>(kv.second); cg.AddFunction(f); }
// Add __tvm_main__ if (aot_executor_fn.defined()) { cg.AddFunction(aot_executor_fn); }
// NOTE: it's possible that kRuntime attr is not attached when the mod was built with tvm.build(). // See issue #10373. auto opt_runtime = mod->GetAttr<relay::Runtime>(tvm::attr::kRuntime); relay::Runtime runtime; if (opt_runtime.get() != nullptr) { runtime = opt_runtime.value(); } else { runtime = relay::Runtime::Create("cpp", {}); } if (aot_executor_fn.defined() && runtime->name == relay::kTvmRuntimeCpp) { cg.InitGlobalContext(); }
if (target->GetAttr<Bool>("system-lib").value_or(Bool(false))) { ICHECK_EQ(target->GetAttr<String>("runtime").value_or(""), "c") << "c target only supports generating C runtime SystemLibs"; } // cg.Finish()是核心的函数,将IRModule Lower为c代码 std::string code = cg.Finish(); // 编译c代码并创建runtime::Module wrapper。 returnCSourceModuleCreate(code, "c", cg.GetFunctionNames()); }




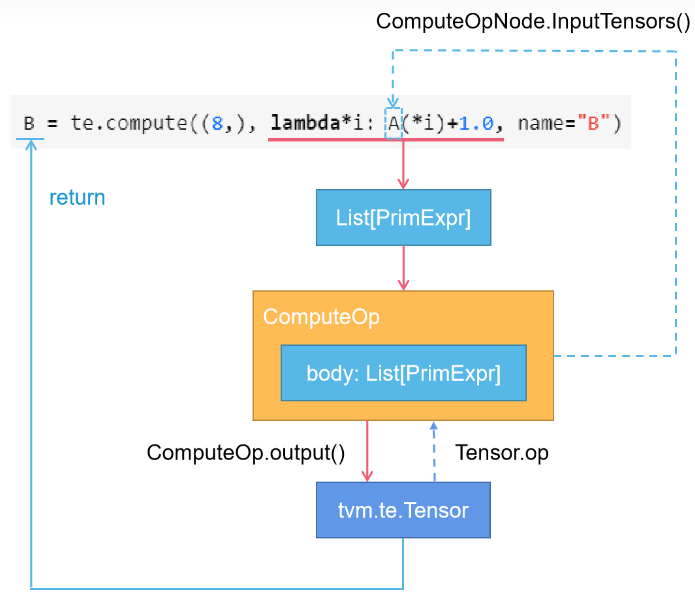 我们从上往下看,这里的List[PrimExpr]就是这个lambda表达式中的PrimExpr集合,第一个PrimExpr是A(*i),第二个PrimExpr是1.0,然后+对应了TIR中的ExprOp(
我们从上往下看,这里的List[PrimExpr]就是这个lambda表达式中的PrimExpr集合,第一个PrimExpr是A(*i),第二个PrimExpr是1.0,然后+对应了TIR中的ExprOp(