前言
本文使用的YOLOv5版本为v6.1,根据不同的了解情况查看对应的文章。
-
Post not found: yolo系列/简单谈谈yolov5-6-x-网络模型(含代码) 简单谈谈yolov5-6-x-网络模型(含代码)
-
Post not found: yolo系列/yolov5魔改教程之backbone yolov5魔改教程之backbone
-
Post not found: yolo系列/yolov5魔改教程之注意力机制 yolov5魔改教程之注意力机制
YOLOv5是Ultralytics公司的开源项目,点击查看项目地址,更新速度非常快,最新版的v6.1于2022年2月22日发布,目前star数22.7k。
YOLOv5更新日志:
2020年6月26日发布v1.0
… … …
2021年4月12日发布v5.0
2021年10月12日发布v6.0
2022年2月22日发布v6.1
下面对v6.x版本的网络模型及各个组件,结合源码和网络框图进行解析。
整体网络结构
v5.x网络结构

v6.x网络结构
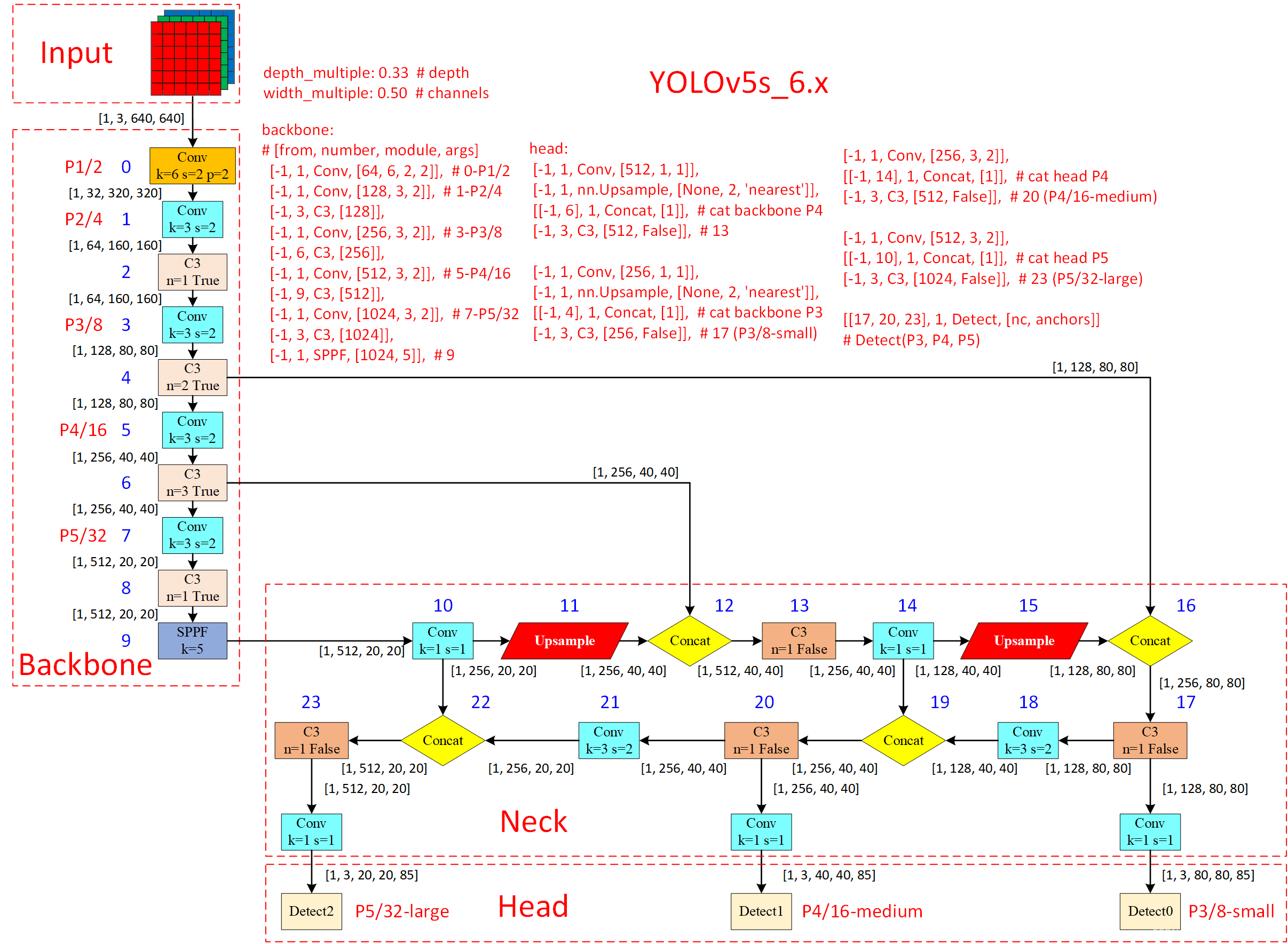
可以看出,相比于之前v5.x,最新版的v6.x网络结构更加精简(以提高速度和推理性能),主要有以下更新:
- Conv(k=6, s=2, p=2) 替换Focus,便于导出其他框架
for improved exportability
- SPPF代替SPP,并且将SPPF放在主干最后一层
for reduced ops
- 主干中的C3层重复次数从9次减小到6次
for reduced ops
- 主干中最后一个C3层引入shortcut
各部分源码解析
YOLOv5网络搭建的各个组件主要在 model/common.py文件中
Conv
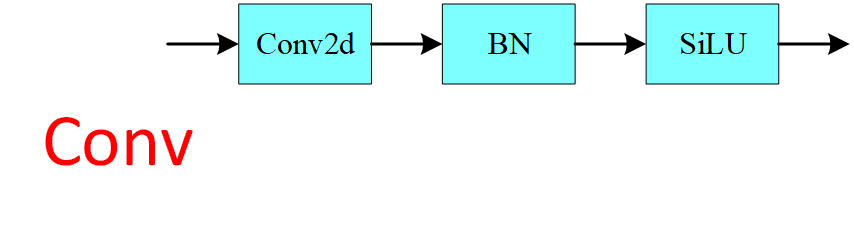
网络中的标准卷积层,有2D Conv+BN+激活函数 SiLU组成,在之后的 Bottleneck、C3、SPPF等结构中都会被调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
|
Focus

Focus模块是作者自己设计出来,为了减少浮点数和提高速度,而不是增加featuremap的,本质就是将图像进行切片,类似于下采样取值,将原图像的宽高信息切分,聚合到channel通道中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| class Focus(nn.Module):
"""理论:从高分辨率图像中,周期性的抽出像素点重构到低分辨率图像中,即将图像相邻的四个位置进行堆叠,
聚焦wh维度信息到c通道中,增大每个点的感受野,减少原始信息的丢失,该模块的设计主要是减少计算量加快速度
Focus wh information into c-space 把宽度w和高度h的信息整合到c空间中
1. 先做4个slice 再concat 最后再做Conv
2. slice后 (b,c1,w,h) -> 分成4个slice 每个slice(b,c1,w/2,h/2)
3. concat(dim=1)后 4个slice(b,c1,w/2,h/2)) -> (b,4c1,w/2,h/2)
4. conv后 (b,4c1,w/2,h/2) -> (b,c2,w/2,h/2)
"""
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
def forward(self, x):
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
|
Bottleneck
标准的bottleneck模块,用在构建BottleneckCSP和C3等模块中,包含shortcut,起到加深网络的作用。

1
2
3
4
5
6
7
8
9
10
11
| class Bottleneck(nn.Module):
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
|
C3
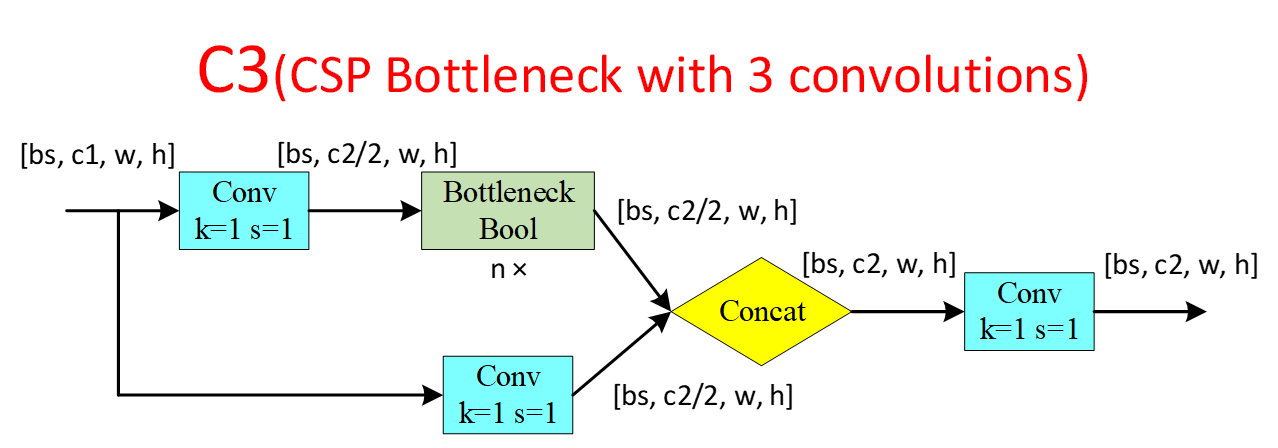
C3模块其实是简化版的 BottleneckCSP,该部分除了 Bottleneck之外,只有3个卷积模块,可以减少参数,所以取名C3。
作者用意为:C3() is an improved version of CSPBottleneck().
It is simpler, faster and and lighter with similar performance and better fuse characteristics.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| class C3(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
|
SPP
Spatial Pyramid Pooling (SPP),SPP层将更多不同分辨率的特征进行融合,在送入网络neck之前能够得到更多的信息。

1
2
3
4
5
6
7
8
9
10
11
12
13
| class SPP(nn.Module):
def init(self, c1, c2, k=(5, 9, 13)):
super().init()
c_ = c1 // 2
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k]) def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
|
SPPF
Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher。SPP-Fast顾名思义就是为了保证准确率相似的条件下爱,减少计算量,以提高速度,使用 3个5×5的最大池化,代替原来的 5×5、9×9、13×13最大池化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| class SPPF(nn.Module):
def init(self, c1, c2, k=5):
super().__init__()
c_ = c1 // 2
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2) def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
|
Reference
【YOLOV5-5.x 源码解读】
yolov5s-6.0网络模型结构图
YOLOv5 v6.0 release 改动速览



